Swap out problem on NUMA architecture
20 Aug 2014We hit a problem on our production servers. It looks like this:
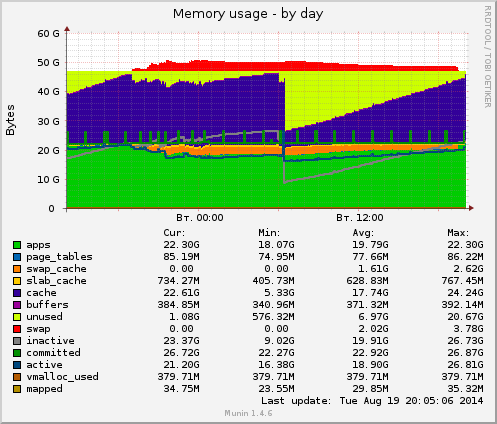
Server has 3 memcached instances installed for 3*4GB = 12GB and 2 redis instances installed for 4GB + async saves through out fork syscall every 10-30 minutes + some other services installed. There are 48GB of memory in total.
It’s NUMA architecture, 2 cpus => 2 mem banks, 10/21 memory bank access, default policy = local, all processes not pinned start at first mem socket.
Server is Ubuntu 12.04.3 LTS with kernel Linux 3.2.0-24-generic #37-Ubuntu SMP x86\_64
vm.swappiness = 0
vm.zone_reclaim_mode = 0
default numa policy
Picture above tells the story. When memory heavy processes hit
24GB memory cap (this is amount of memory on each memory socket)
(case is N0 is exhausted, see numactl -H)
OS memory scheduler swaps out those memory even in a case, there is 24 gb
of free memory owned by the buffer cache on the secondary memory socket.
As can be seen, there is 22.61GB of cache right now. It filled with nginx access logs (>10GB uncompressed -> 3GB rotated) which will be rotated / compressed at 6 o’clock.
Interesting thing is, when swapping in all the memory with swapoff -a && swapon -a,
memory from the swap will be partially placed into another memory zone. (OOM
will occur if some process suddenly will start to reserve corresponding
amounts of memory blocks)
Why is that happening?
Kernel can’t dynamically move pages among zones. The only thing it can is to allocate/release pages of memory in certain memory zones determined by corresponding memory policy.
When someone in a zone needs memory, kernel have to get some. Memory can be obtained by swapping out some process memory from zone, or running OOM killer in a zone.
In our case, we have all memory exhausted in the first zone, and whole free second. So, we need to better distribute processes among zones. There are 2 parameters affects memory distribution:
- zone reclaimation policy
- numa memory distribution policy
Possible solution
Change memory distribution policy (i.e. interleave, zone_reclaim_mode = 1) or pin some process to allocate their memory on another socket.
What we done
We pinned 3 memcached processes to use PREFERED memory policy and to start memory allocation on second node. This will allocate 12GB of memory on the second cpu.
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 8 9 10 11
node 0 size: 24567 MB
node 0 free: 2938 MB
node 1 cpus: 4 5 6 7 12 13 14 15
node 1 size: 24576 MB
node 1 free: 11000 MB
node distances:
node 0 1
0: 10 21
1: 21 10
$ numactl --cpunodebind=1 --preferred=1 -- memcached
How to check out memory map distribution over zones
Use modifiend numa_map_summary.pl to get your memory distribution over memory zones.
$ sudo ./numa_map_summary.pl top 15
PID: 16821 : N0 : 101349 ( 0.39 GB), N1 : 981166 ( 3.74 GB)
PID: 16829 : N0 : 117047 ( 0.45 GB), N1 : 965419 ( 3.68 GB)
PID: 22632 : N0 : 995014 ( 3.80 GB), N1 : 76228 ( 0.29 GB)
PID: 16813 : N0 : 60841 ( 0.23 GB), N1 : 755779 ( 2.88 GB)
PID: 22561 : N0 : 144255 ( 0.55 GB), N1 : 338 ( 0.00 GB)
PID: 23645 : N0 : 19340 ( 0.07 GB), N1 : 5584 ( 0.02 GB)
PID: 23464 : N0 : 15254 ( 0.06 GB), N1 : 3321 ( 0.01 GB)
PID: 28100 : N0 : 11455 ( 0.04 GB), N1 : 6756 ( 0.03 GB)
PID: 23466 : N0 : 16458 ( 0.06 GB), N1 : 1480 ( 0.01 GB)
PID: 28096 : N0 : 15860 ( 0.06 GB), N1 : 2065 ( 0.01 GB)
PID: 28097 : N0 : 10270 ( 0.04 GB), N1 : 7275 ( 0.03 GB)
PID: 23636 : N0 : 10753 ( 0.04 GB), N1 : 6384 ( 0.02 GB)
PID: 4629 : N0 : 9105 ( 0.03 GB), N1 : 8032 ( 0.03 GB)
PID: 23463 : N0 : 13528 ( 0.05 GB), N1 : 3407 ( 0.01 GB)
PID: 20125 : N0 : 8397 ( 0.03 GB), N1 : 8506 ( 0.03 GB)
Total: N0 : 1548926 (5.90868377685547 GB) N1 : 2831740 (10.8022308349609 GB)
Documentation
Take a look at a description of vm.zone_reclaim_mode parameter.
zone_reclaim_mode:
Zone_reclaim_mode allows someone to set more or less aggressive approaches to reclaim memory when a zone runs out of memory. If it is set to zero then no zone reclaim occurs. Allocations will be satisfied from other zones / nodes in the system.
This is value ORed together of
1 = Zone reclaim on
2 = Zone reclaim writes dirty pages out
4 = Zone reclaim swaps pages
zone_reclaim_mode is disabled by default. For file servers or workloads that benefit from having their data cached, zone_reclaim_mode should be left disabled as the caching effect is likely to be more important than data locality.
zone_reclaim may be enabled if it’s known that the workload is partitioned such that each partition fits within a NUMA node and that accessing remote memory would cause a measurable performance reduction. The page allocator will then reclaim easily reusable pages (those page cache pages that are currently not used) before allocating off node pages.
Allowing zone reclaim to write out pages stops processes that are writing large amounts of data from dirtying pages on other nodes. Zone reclaim will write out dirty pages if a zone fills up and so effectively throttle the process. This may decrease the performance of a single process since it cannot use all of system memory to buffer the outgoing writes anymore but it preserve the memory on other nodes so that the performance of other processes running on other nodes will not be affected.
Allowing regular swap effectively restricts allocations to the local node unless explicitly overridden by memory policies or cpuset configurations.
So, it may be beneficial to switch off zone reclaim if the system is used for a file server and all of memory should be used for caching files from disk. In that case the caching effect is more important than data locality.
To read
PostgreSQL, NUMA and zone reclaim mode on linux
Optimizing Linux Memory Management for Low-latency / High-throughput Databases
OOM relation to vm.swappiness=0 in new kernel
In the Linux kernel, “memory policy” determines from which node the kernel will allocate memory in a NUMA system or in an emulated NUMA system.
System Default Policy: this policy is “hard coded” into the kernel. It is the policy that governs all page allocations that aren’t controlled by one of the more specific policy scopes discussed below. When the system is “up and running”, the system default policy will use “local allocation” described below. However, during boot up, the system default policy will be set to interleave allocations across all nodes with “sufficient” memory, so async not to overload the initial boot node with boot-time allocations.